Extract Information from PDF
Description
You can extract information from your PDF File.
Input Arguments
| Input Argument | Type | Description | Required? | Advanced Option? | Default |
|---|---|---|---|---|---|
File | The file from which information shall be extracted. File only – no string/Base64 allowed | ✔️ | ❌ | - |
Output
| Response | Type | Description |
|---|---|---|
Author | String | Name of the author of the PDF. |
Creator | String | Software used to create the PDF. |
Producer | String | Software or tool that produced the final PDF output. |
Subject | String | Subject metadata of the PDF (if defined). |
Title | String | Title metadata of the PDF (if defined). |
Keywords | String | Any keywords associated with the PDF. |
CreationDate | Number | Timestamp of when the PDF was created. |
ModificationDate | Number | Timestamp of the last modification. |
FileSize | Number | File size in bytes. |
PDFVersion | Number | Version of the PDF specification used. |
PageCount | Number | Total number of pages in the PDF. |
Body | Object | Full JSON object containing all extracted information. Useful for variables. |
Power Automate Examples
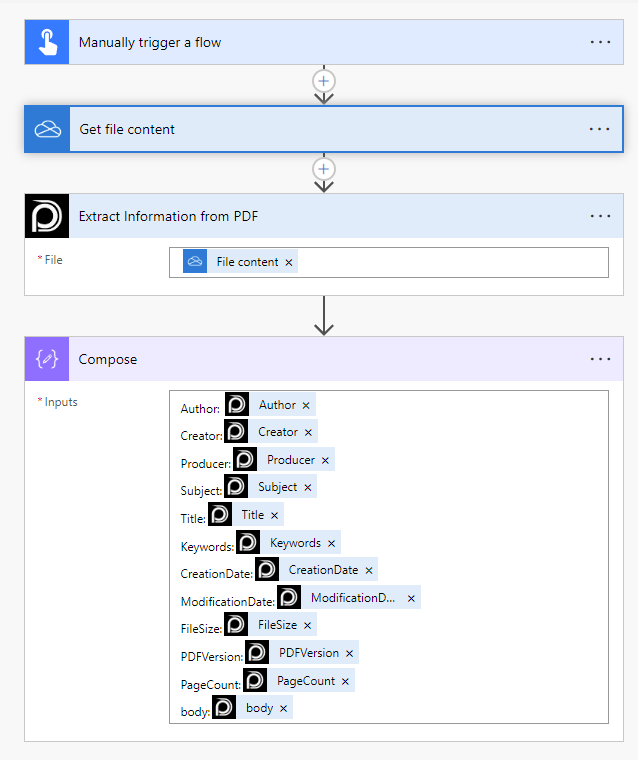
Extract Information from PDF
We use the Get file content action to retrieve PDF File from our OneDrive as input and extract information from it. Therafter, we use the information as dynamic content.
💡
Looking for the response to this example? Scroll up to see the Output tab.
Known Limitations
⚠️
If you experienced other limitations please get in touch with us!